2026. 5. 25. 13:19ㆍAI/LLM
앞서 우리는 트랜스포머 라이브러리로 파이프라인에 Task 매개변수로 집어넣어서
인코더, 디코더 과정을 거쳐 Task를 수행해주는 모델을 만들어 봤다.
이제는 그 파이프라인 함수 안에서는 어떻게 동작하는지 알아보자.
모델에 대해 이해하는데 도움이 될 것이다.
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a Hugging face course my whole life.",
"I hate this so much."
]
)
앞서 살펴보았던 감정 분석의 예시이다.

결과는 다음과 같이 나올 것이다.
이제 이 내부 원리 과정을 자세히 살펴보자.
1. 토크나이저(토큰화) : 문장을 숫자로 변환하는 작업
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" # 모델명
tokenizer = AuthoTokenizer.from_pretrained(checkpoint)
앞서 토큰화는 문장을 나누는 것이라고 설명했는데 그 방식이 단어 기반도 있겠지만
서브워드 토큰화 알고리즘도 존재한다.
자주 사용되는 단어는 더 작은 서브워드로 나누면 안되지만,
희귀한 단어는 의미있는 서브워드로 나눠야 한다.
다음과 같은 규칙에 기반하는 것이다.
예를 들어, Let's do Tokenization 이라는 문장을 어떻게 토큰화 하는지 알아보자.

서브 워드는 많은 양의 의미론적인 정보를 제공하는데,
위의 예시에서 tokenization는 의미론적인 정보를 갖는 2개의 토큰 "token"과 "ization"으로 분할되었고,
긴 단어를 두 단어만으로 표현할 수 있어 공간효율적이다.
이 방식을 통해 크기가 작은 단어 사전만으로도 많은 토큰을 표현할 수 있고, unknown 토큰도 거의 없다.
그래서 위의 토큰화 알고리즘에 따라 모델을 써서
여러 개의 토큰으로 나누는 작업인 것이다.
그럼 실제로 어떻게 나뉘는지 결과를 통해 살펴보자.
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!"
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
여기서 tokenizer() 함수는 문자를 토큰으로 분할해주는 역할인데, 지금 구조에서 보면
첫번째 인덱스 문장의 길이가 더 길고, 두번째 인덱스 문장은 길이가 짧다.
그래서 토큰 구조의 길이를 맞추기 위해 더 큰 토큰의 크기 만큼 맞춘다
(빈 부분은 0으로 채우는 것)
그 맞추는 과정을 패딩(Padding) 이라고 한다.
그리고 truncation의 의미는 처리할 수 있는 문장의 크기가 제한되어 있는 모델에서
모델이 지원하는 최대 시퀀스 길이에 맞춰서 잘라내는 옵션이다.
return_tensor는 토큰화 된 후 Pytorch Tensor로 반환해준다는 의미이다.
그럼 위에서 토큰화된 숫자의 의미는 무엇일까?
예를 들어, "hello"를 토큰화 했을 때의 의미는 다음과 같다.

즉, 101과 102 사이에 있는 의미심장한 숫자들은 모두 문장들을 토큰화한 숫자들이고,
101과 102는 각각 문장의 시작과 끝을 의미하는 것이다.
그리고, 이 과정을 임베딩이라고 부르기도 한다.
2. 모델 삽입 (전처리 과정) : AutoModel
앞서 토큰화된 input을 모델에 넣어주는 작업이다. 반환값으로 PyTorch를 받는다.
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
outputs = model(**inputs) # 여기서 inputs는 토큰화된 Tensor
print(outputs.last_hidden_state.shape)
다음 반환값이 의미하는 것은
torch.Size[batch Size, Sequence Length, Hidden Size]를 의미한다.
Batch Size는 토큰화된 문장의 개수(토큰 하나 당이 아닌 문장 하나당 1개로 체크)이고 (2)
Sequence Length는 위에서 큰 문장에 맞춘 토큰의 길이로 보면 된다. (16)
Hidden Size는 벡터화 시킬때 몇 개의 차원으로 나올지 지정하는 숫자이다 (768)
3. 태스킹
이제 위 벡터화된 데이터를 넣어서 전처리 과정을 거친 후 본격적으로 태스킹 작업이 진행되는데
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
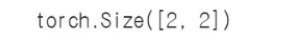
다음은 inputs로 보낸 2개의 문장과 결과로 나온 2개의 Label(긍정, 부정)을 의미하는 것이다.
outputs.logit
위는 설명하자면 복잡하지만, 간단하게 말해서 위의 레이블 중에 하나일 확률 정도로 이해하면 편하다.
(긍정일 확률 x%, 부정일 확률 y%를 벡터 데이터로 표현)
그러나 위 데이터로는 사람이 이해하지 못하므로, 자연어로 처리해주어야 한다.
4. 자연어 처리
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
'AI > LLM' 카테고리의 다른 글
| 허깅 페이스(Hugging Face) - 트레이너 API (4) (0) | 2026.05.28 |
|---|---|
| 허깅 페이스(Hugging Face) - 데이터 파인튜닝 프로세싱 (3) (0) | 2026.05.28 |
| AI 활용 - 클로드 코드 스킬(Claude Code Skills)이란? (0) | 2026.05.27 |
| AI 활용 - 클로드 코드로 AI 개발 워크플로우 짜기 (0) | 2026.05.25 |
| 허깅 페이스(Hugging Face) - 기본 개요 (1) (0) | 2026.05.25 |