2026. 5. 28. 00:00ㆍAI/LLM
우리가 현재 사용하고 있는 LLM 모델들은 Pre-Training(사전학습)된 모델이다.
이 모델을 우리는 파운데이션 모델(Foundation Model) 이라고 부른다.
예를 들어 법률에 대해 질의응답이 가능한 모델로 만들고 싶을 경우
법률 문서 혹은 법률에 관한 질의응답이 있는 데이터들을 넣어서 추가 학습을 시켜야 한다.
이것을 파인 튜닝(Fine-Tuning) 이라고 부른다.
여기서 살펴볼 것은 파인 튜닝에 관한 내용이다.
감정 분석(긍정, 부정) / 문장 유사도 / 뉴스 분류 / 스팸 분류 등..
같은 작업을 담당하는 모델은 어떻게 훈련되는지 코드로 살펴볼 것이다.
import torch
from torch.optim import AdamW
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# 앞에서 한 내용과 같음
checkpoint = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = [
"I've been waiting for a HuggingFace course my whole life.",
"This Course is Amazing!"
]
batch = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
이 부분은 앞서 사전 훈련된 모델을 통해 토큰화 시켜 처리하는 과정을 나타낸 것이다.
그 뒷 부분을 살펴보자.
batch['labels'] = torch.tensor([1, 1])
optimizer = AdamW(model.parameters())
loss = modl(**batch).loss
loss.backward()
optimizer.step()
batch의 label 항목을 통해 실제 정답을 제공받는다.
그리고, AdamW 함수를 통해 모델이 틀린 정도를 보고 가중치를 수정하는 최적화 작업을 거친다.
모델의 틀린 정도를 변수로 받아, 수정할 부분으로 되돌아가서 수정을 진행한다. (역전파)
다시 가중치를 업데이트하고 학습 진행을 반복한다.
실제적인 파인 튜닝 단계라고 보면 된다. 수십번 학습을 통해 오차를 최소화 시키는 과정이다.
이제 실제 데이터셋을 불러서 단계별로 자세히 어떻게 이뤄지는지 살펴보자.
from datasets import load_dataset
raw_datasets = load_dataset("glue","mrpc")
raw_datasets
이 결과는 자연어 처리 성능 평가용 데이터라고 이해하면 편하다.
자세히는 두 개의 문장이 같은 의미인지 판단하는 데이터셋이다.
우리는 이런 데이터셋을 불러와 파운데이션 모델에 직접 학습을 시켜야 한다.
학습을 시킬 때 어떤 과정으로 진행되냐면, 시험에 대비해 기출 문제를 풀듯이 학습 데이터를 넘겨주는데
그 과정을 train이라고 한다. 기출문제를 기반으로 모의고사를 보듯이 test 항목이라고 보면 된다.
이 과정을 스위칭 하듯이 왔다갔다하는 과정이다.
그럼 먼저 train에 어떤 데이터가 들어있는지 확인해보자.
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
문장 2개가 같이 들어가고, label을 통해 유사도를 판단하는 구조로 되어있다.
이런 식으로 학습할 수 있는 데이터를 넘겨주는 것이다.
이제 이 데이터를 기반으로 학습을 시키려면 앞에서 했던 내용들을 반복해야 하는 것이다.
from transformers import AutoTokenizer
checkpoint = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 컬럼별로 넘긴다.
tokenized_setences_1 = tokenizer(list(raw_datasets["train"]["sentence1"]))
tokenized_sentences_2 = tokenizer(list(raw_datasets["train"]["sentence2"]))
# 한번에 넘긴다
tokenized_dataset = tokenizer(
list(raw_datasets['train']['sentence1']),
list(raw_datasets['train']['sentence1']),
padding=True,
truncation=True
)
# 함수로 구현한다
def tokenize_function(array):
return tokenizer(array["sentence1"], array["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
토큰을 넘길 때 컬럼별로 넘기는 방법과 한번에 넘기는 방법, 함수로 구현하는 방법이 있는데 자세한 코드는 위를 참조하자.
중요한건 이런 과정을 통해 토큰화 시키는 작업을 여러가지로 설명한 것이라고 보면 된다.
하지만 매번 이렇게 구현하는 것은 복잡하므로, 아래와 같은 과정으로 통합했다.
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
서로 데이터 차이가 클 경우, 패딩값이 많아져 메모리 낭비가 되는 문제가 생길 수 있는데
그래서 Batch 단위로 가장 긴 길이를 설정 해놓은 후, 그것을 못 넘어가게 설정해서 패딩처리를 해야 한다.
그것을 발전시켜 적용한 것이 위 함수라고 보면 된다.
여기서 Batch는 병렬 처리 가능한 연산으로써 가능한 학습 단위로 이해하면 좋다.
다음 코드를 통해 예시로 이해해보자.
samples = tokenized_datasets['train'][:8]
samples = { k: v for k,v in samples.items() if k not in ["idx","sentence1","sentence2"]}
[len(x) for x in samples["input_ids"]]
batch = data_collator(samples)
{ k: v.shape for k,v in batch.items()}
다음 결과는 samples 변수(앞에 긴 문장을 앞 8개만 자른 변수)를 data_collator 함수에 넣었을 때,
(data_collator는 앞서 말한 Batch 단위로 패딩 처리하는 함수)
가장 긴 67개의 토큰으로 패딩이 맞추어져 있었다는 내용이다.
이게 하나의 Batch에서는 67개였지만, 다음 Batch에서는 그 크기가
줄어들수도 있다는 것은 명심해야 한다.
이렇게 파인튜닝을 미세조정하는 과정을 거치고 나서 끝이냐? 그것은 아니다.
실제 시험에서 결과가 나오는 것처럼 학습 평가 과정이 필요하다.
그 중 하나가 손실 곡선 개념이다.

처음에는 많은 loss가 나타나다가 여러번 미세 조정을 거치면서 loss가 줄어든다는 개념이다.
그 다음은 정확도 곡선이다.
처음에는 정확도가 낮다가 훈련이 진행되면서 정확도가 점점 올라간다는 개념이다. (예측률 증가)
그 과정에서 나온 개념이 과적합인데 모델이 훈련 데이터에서 너무 많이 학습하면
다른 데이터로 일반화 할 수 없는 지경에 이르는 개념이다. (모의고사는 못 보는 현상)

반대로 과소적합은 데이터가 너무 작게 주어져 패턴 자체를 배우지 못하는 개념을 과소적합이라고 한다.
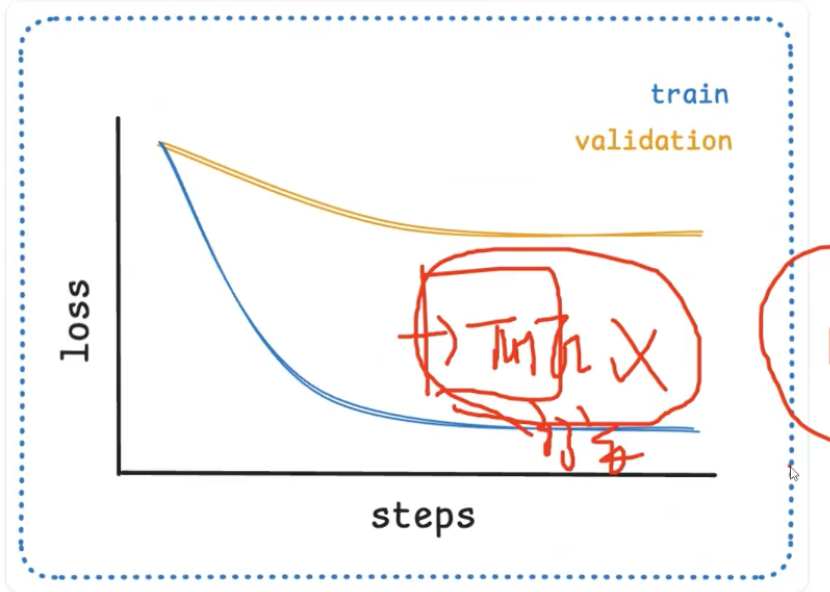
결론적으로는 이런 개념들을 적용하여 평가 단계를 거쳐 최종 수렴하는 단계까지 가야한다.
그렇게 되면 쓸 수 있는 모델이 되는 것이다.

'AI > LLM' 카테고리의 다른 글
| 허깅 페이스(Hugging Face) - 멀티 모달 (5) (0) | 2026.06.02 |
|---|---|
| 허깅 페이스(Hugging Face) - 트레이너 API (4) (0) | 2026.05.28 |
| AI 활용 - 클로드 코드 스킬(Claude Code Skills)이란? (0) | 2026.05.27 |
| AI 활용 - 클로드 코드로 AI 개발 워크플로우 짜기 (0) | 2026.05.25 |
| 허깅 페이스(Hugging Face) - 파이프라인의 원리 (2) (0) | 2026.05.25 |